近期,AI領域迎來了一場重大變革,DeepSeek憑借其卓越的性能、成本控制以及易用性,成功吸引了騰訊、百度等互聯網巨頭的青睞。兩大互聯網巨頭先后將DeepSeek接入其生態系統,使其在微信搜索和百度搜索兩大超級入口中占據了席之地,影響力瞬間覆蓋數億用戶。
這一舉動背后,透露出傳統互聯網巨頭在AI時代下的無奈與被動。盡管自研模型一直是巨頭們的首選,但DeepSeek在多方面展現出的優勢,讓巨頭們不得不重新審視自己的戰略。接入DeepSeek,成為了它們維持競爭力的權宜之計。
同時,巨頭們也在積極尋求通過生態整合和組織變革,將DeepSeek轉化為自身的競爭優勢。這一戰略選擇,不僅是對現有生態的快速整合,更是對先進技術的一次深度擁抱,旨在鞏固和提升自己的市場地位。
自生成式AI誕生以來,AI大模型在功能集成方面一直難以做到深度場景化應用。這主要是因為,要實現真正的場景化AI,需要打通大量的數據孤島和應用場景,而這些數據和場景往往被不同的互聯網平臺所分割。據IDC報告顯示,中國互聯網行業的數據存儲量中,73%集中在騰訊、阿里、字節等TOP10平臺,但跨平臺數據調用的成功率卻不足5%。

以搜索為例,現有的頭部模型雖然具備聯網搜索功能,但所能抓取的大都是公域信息,對于私域內容,如公眾號平臺的數據,則難以觸及。只有騰訊自家的元寶模型能夠做到這一點。這種私有流量池的存在,使得大量用戶的閱讀興趣、瀏覽記錄等數據被牢牢掌控。
百度APP作為全球最大的中文搜索引擎,擁有7億用戶,集成了搜索、地圖、貼吧、網盤、文庫、知道、健康等20多項功能。用戶在搜索框鍵入文字時,需求可能不僅僅是信息查閱,而是多種功能和場景的交互結果。這種跨場景的連接能力,是第三方AI難以實現的。
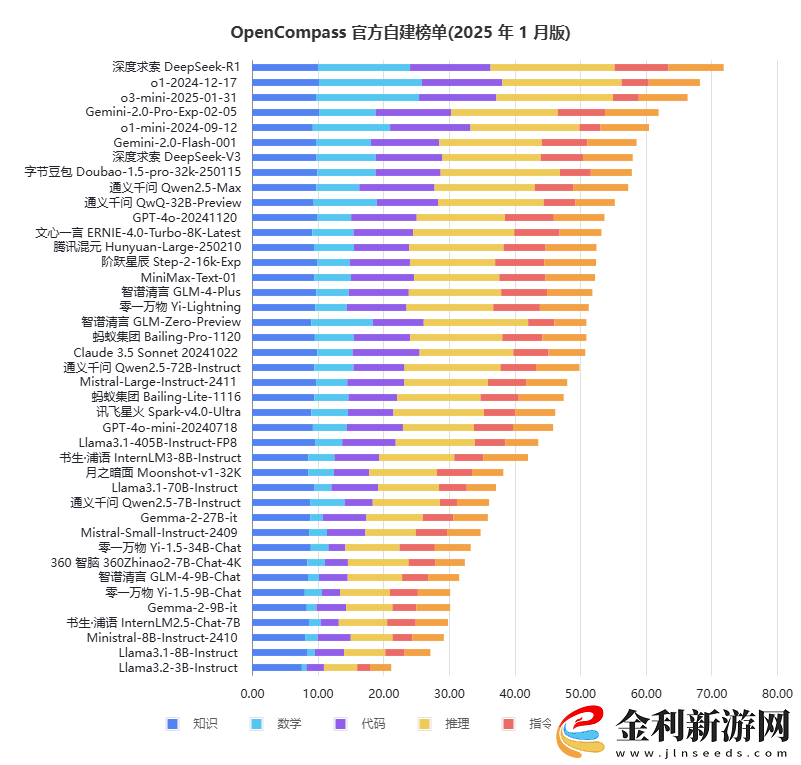
然而,掌握著龐大數據和應用場景的巨頭們,其AI模型的表現卻往往不盡如人意。司南大模型榜單顯示,騰訊的文心一言與混元模型明顯落后于DeepSeek-R1。這形成了傳統互聯網巨頭“有入口但模型拉胯”,AI企業“模型強卻無入口”的割裂局面。
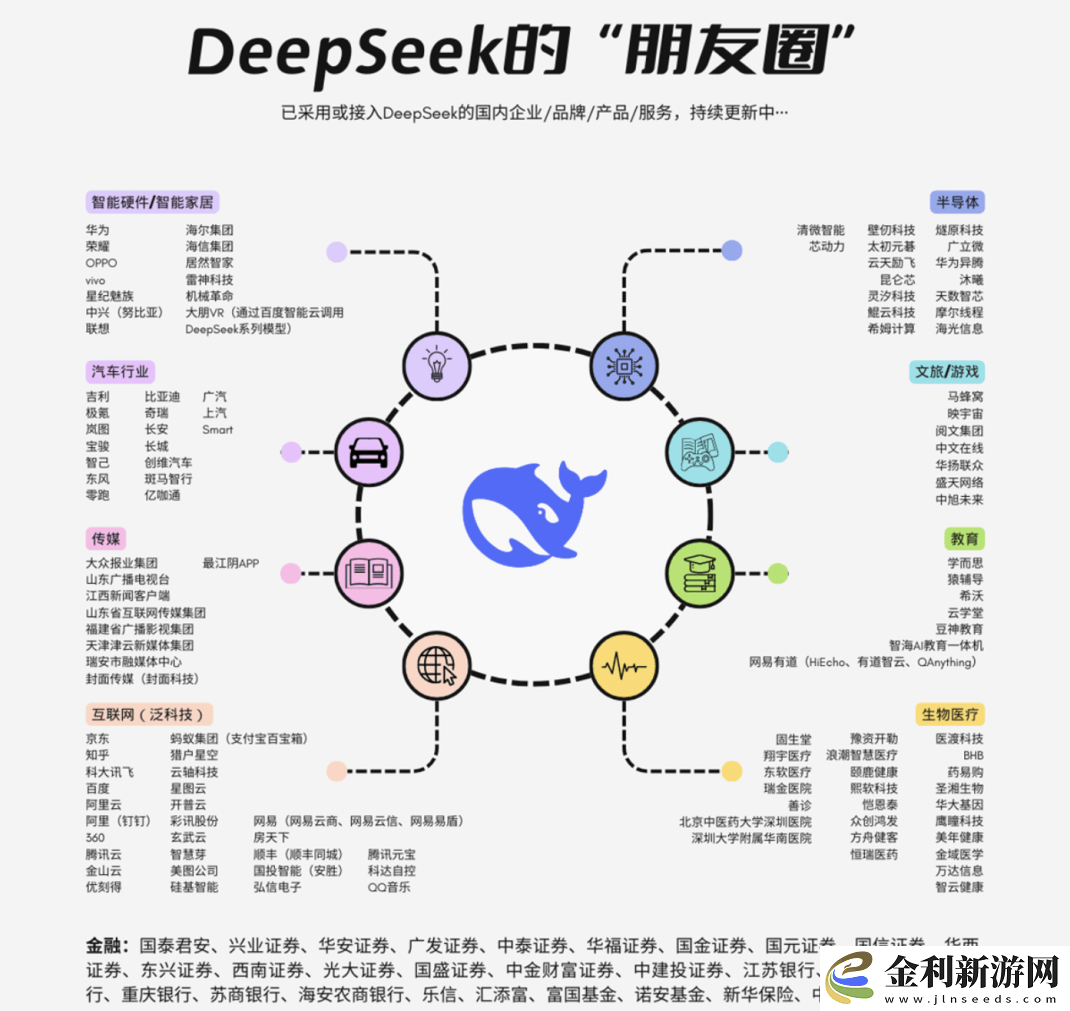
DeepSeek-R1的問世,徹底改變了這一局面。憑借其強大的性能和低廉的成本,DeepSeek的“生態朋友圈”迅速擴大,覆蓋了智能硬件、汽車、傳媒、互聯網、半導體等多個行業。各大巨頭也意識到,未來的AI領域,很可能將由一兩個在性能和成本上兼具優勢的“超級模型”主導。
盡管接入了DeepSeek,但騰訊、百度等巨頭并未放棄自研模型。騰訊元寶在接入DeepSeek后不久,就更新了APP,上線了混元的推理模型T1。巨頭們試圖在外部技術和自主可控之間尋求平衡,避免因過度依賴第三方模型而失去技術制高點。

然而,DeepSeek-R1的開源并不意味著競爭對手可以輕易復現其性能。其MoE架構和“多頭潛在注意力”機制需要大量的測試數據和強化學習優化的實戰經驗作為支撐。這背后凝結的是高深的工程學經驗,使得DeepSeek-R1成為一種易學難精的技術。
DeepSeek之所以能吸引一批具有海外經驗的頂尖AI人才加入,得益于其扁平、靈活的組織架構。這種組織架構上的優勢,是百度、騰訊等大廠目前所不具備的。而百度在發布2024年全年財報后股價的下跌,也反映出市場對這家老牌搜索巨頭在AI轉型上的疑慮。
在未來的互聯網生態中,“平臺為主”還是“AI優先”的趨勢尚不明朗。但從當前的中國AI競爭格局來看,傳統互聯網巨頭的“數據+場景”護城河難以撼動。未來的破局點,或許在于“數據流動性×場景適配性×商業可行性”的多元平衡。
